

Data Warehouse, Data Lake och Data Lakehouse – vad är skillnaden?
Vi är vana vid termerna data warehouse och data lake, det är två begrepp som är väletablerade inom BI-världen. Data warehouse som är det klassiska sättet för datadrivet beslutsfattande och data lake som är den modernare lagringsytan som har möjliggjort utvecklingen av avancerade analyser. Men nu börjar ett nytt begrepp göra anspråk på att få komma in i värmen – data lakehouse, vilket kan beskrivas som en kombination av de båda föregående begreppen. I denna artikel beskriver jag dessa tre begrepp, vad de innebär och vad som skiljer dem åt.
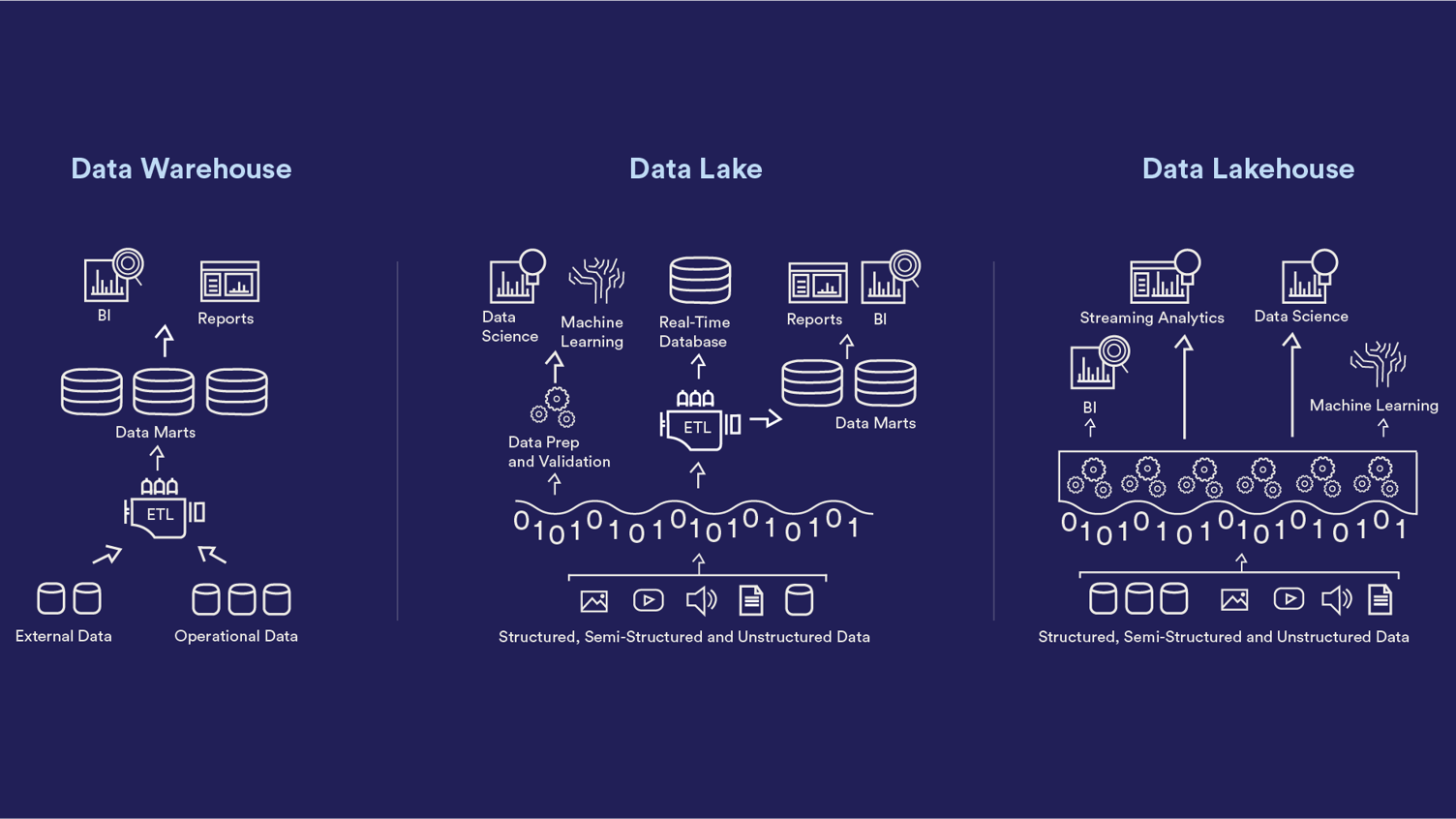
Data warehouse
Begreppet data warehouse har funnits i flera decennier och är ett strukturerat sätt att samla in och analysera sin data på. Traditionellt läses data in från flera källsystem till en relationsdatabas, för att sedan kombineras och byggas till en modell som kan tillhandahållas som underlag för analyser. Många organisationer jobbar med detta sedan flera år tillbaka och är vana vid att ta fram denna typ av rapporter och göra analyser på historisk data som finns att tillgå. Här handlar det framför allt om deskriptiv analys av vad som har hänt. Ett exempel kan vara en rapport som följer upp försäljningssiffror där möjligheten finns att jämföra innevarande månad med samma månad föregående år.
Data lake
Data lake är ett nyare begrepp som etablerat sig det senaste decenniet och som möjliggör lagring av data som inte går att läsa in i en relationsdatabas. En data lake stödjer fler format som bland annat bilder och fritext. Data lake som lagringsplats har ökat i och med att nyttjandet av molntjänster har växt de senaste åren. Och många data scientists har byggt algoritmer för att analysera data som inte passar i en relationsdatabas. Det har medfört att möjligheterna har ökat för att göra mer prediktiva analyser och att försöka säga något om framtiden. Till exempel förutse vilka produkter som kommer ha en ökad efterfrågan så att lagerhållning och transporter kan optimeras.
Data lakehouse
Ett data lakehouse är ett nytt begrepp som myntats de senaste åren och som försöker kombinera de två ovanstående begreppen. Sedan data lake gjorde sitt intåg har nya typer av analyser tagit plats, men på grund av begränsningarna i ett traditionellt data warehouse har dessa sällan kunnat kombineras med analyser därifrån. Genom att kombinera fördelarna av båda världar ökar möjligheterna till synergier däremellan.
I ett data lakehouse används det strukturerade koncept som länge använts inom data warehouse. Data delas upp i flera lager, där en rensning och applicering av regler som gör informationen lättare att läsa och förstå görs mellan varje lager. Genom att tillämpa denna teknik i en data lake så bibehålls möjligheten att även applicera denna struktur på flera format som en data lake stödjer. Konceptet byggs således på data warehouse, men på tekniken av en data lake och nyttjar därmed båda teknikernas fördelar. I och med utvecklingen av data lake och möjligheterna att ansluta och ta del av informationen som finns däri kan både data scientists och data warehouse-utvecklare, som från början är vana vid olika språk, tillgodogöra sig informationen.
Slutsats
Data lakehouse är ett nytt koncept som även introducerar ny teknik. Beroende på behov, datamängd och tillgänglighet så kan ett data lakehouse ge stora fördelar jämfört med ett klassiskt data warehouse. Finns det ett utbrett behov av att kunna kombinera sina deskriptiva och prediktiva analyser, kunna tillgodogöra sig information från strömmande data samt tillgängliggöra datat snabbt till slutanvändare för analyser så kan detta koncept vara fördelaktigt.




